




Китайский ИИ-стартап DeepSeek опубликовал превью новой линейки языковых моделей. Флагманская V4-Pro обошла Claude Opus 4.6 и GPT-5.4.
Китайский ИИ-стартап DeepSeek опубликовал превью новой линейки языковых моделей. Флагманская V4-Pro обошла Claude Opus 4.6 и GPT-5.4, став лучшей открытой системой.
DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. DeepSeek-V4-Flash: 284B total / 13B active params.… pic.twitter.com/n1AgwMIymu
— DeepSeek (@deepseek_ai) April 24, 2026V4-Pro насчитывает около 1,6 трлн параметров, но на каждом шаге использует только 49 млрд. У второй версии — V4-Flash — общий масштаб составляет 284 млрд, из которых активируются 13 млрд.
Обе модели построены на архитектуре «смеси экспертов» (Mixture of Experts, MoE): при обработке каждого токена включается только та часть подсетей, которая релевантна задаче. Такой подход дешевле полностью плотных архитектур, но не уступает им в производительности.
Предобучение проходило на корпусе объемом более 32 трлн токенов. Затем разработчики дообучили модели поэтапно, выделив отдельные блоки для кодинга, математики, логики и следования инструкциям. Финальная версия сводит эти навыки воедино с помощью дистилляции.
Ключевым отличием V4 стала оптимизация обработки длинных последовательностей. Контекстное окно в 1 млн токенов есть и у других моделей, но его использование обычно сопряжено с высокой стоимостью и задержками.
В DeepSeek заявили, что новая версия заметно снизила ресурсоемкость таких операций. По сравнению с V3.2, V4-Pro требует около 27% вычислений и 10% памяти KV-кэша при работе с максимальным контекстом. Для V4-Flash показатели составляют примерно 10% и 7% соответственно.
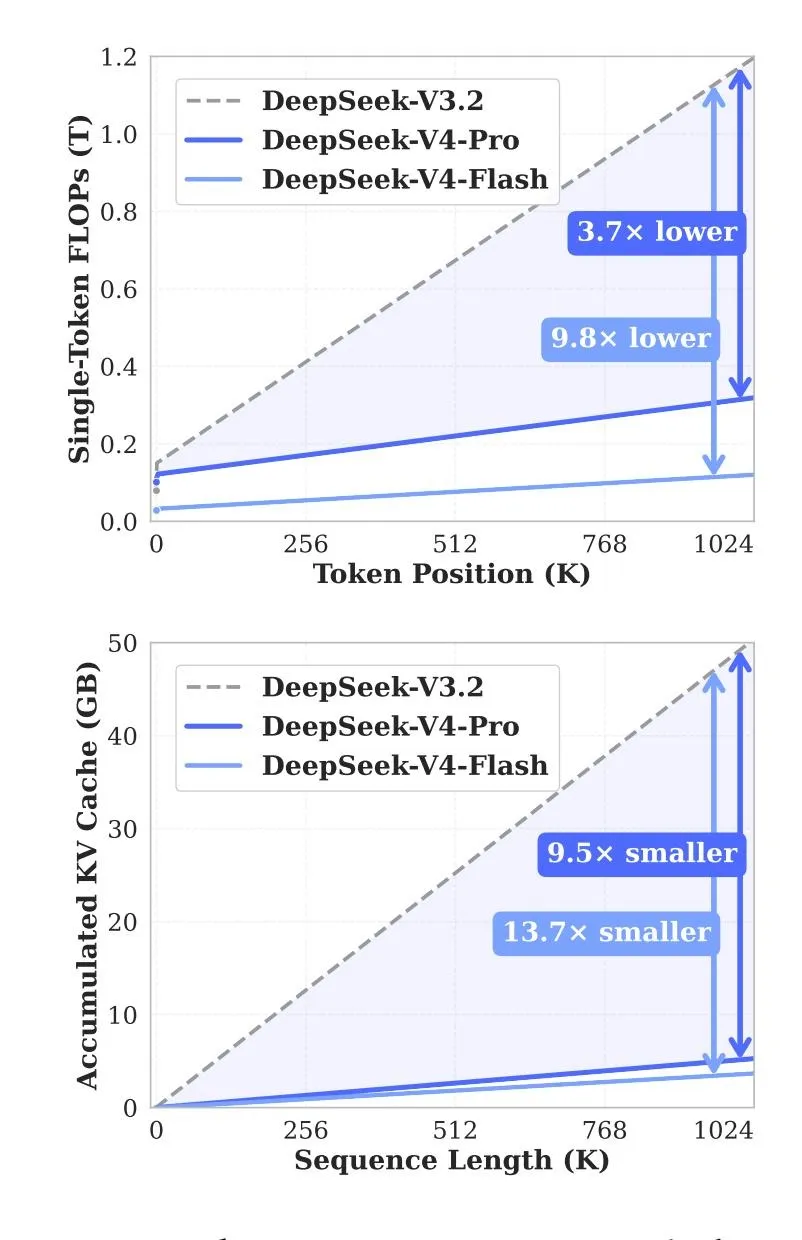 Источник: Hugging Face.
Источник: Hugging Face.
Команда добилась результата благодаря гибридной архитектуре внимания: два механизма сжимают данные и снижают нагрузку при работе с длинными текстами. Также использовались специальные гиперсвязи для стабильности и оптимизатор Muon для ускорения обучения.
DeepSeek V4 поддерживает три режима рассуждений:
В агентных задачах режим Max теперь сохраняет цепочку промежуточных шагов внутри одной задачи. В предыдущей версии часть такого контекста терялась при взаимодействии с пользователем.
По данным DeepSeek, флагманская версия демонстрирует результаты, сопоставимые с ведущими системами в ряде направлений:
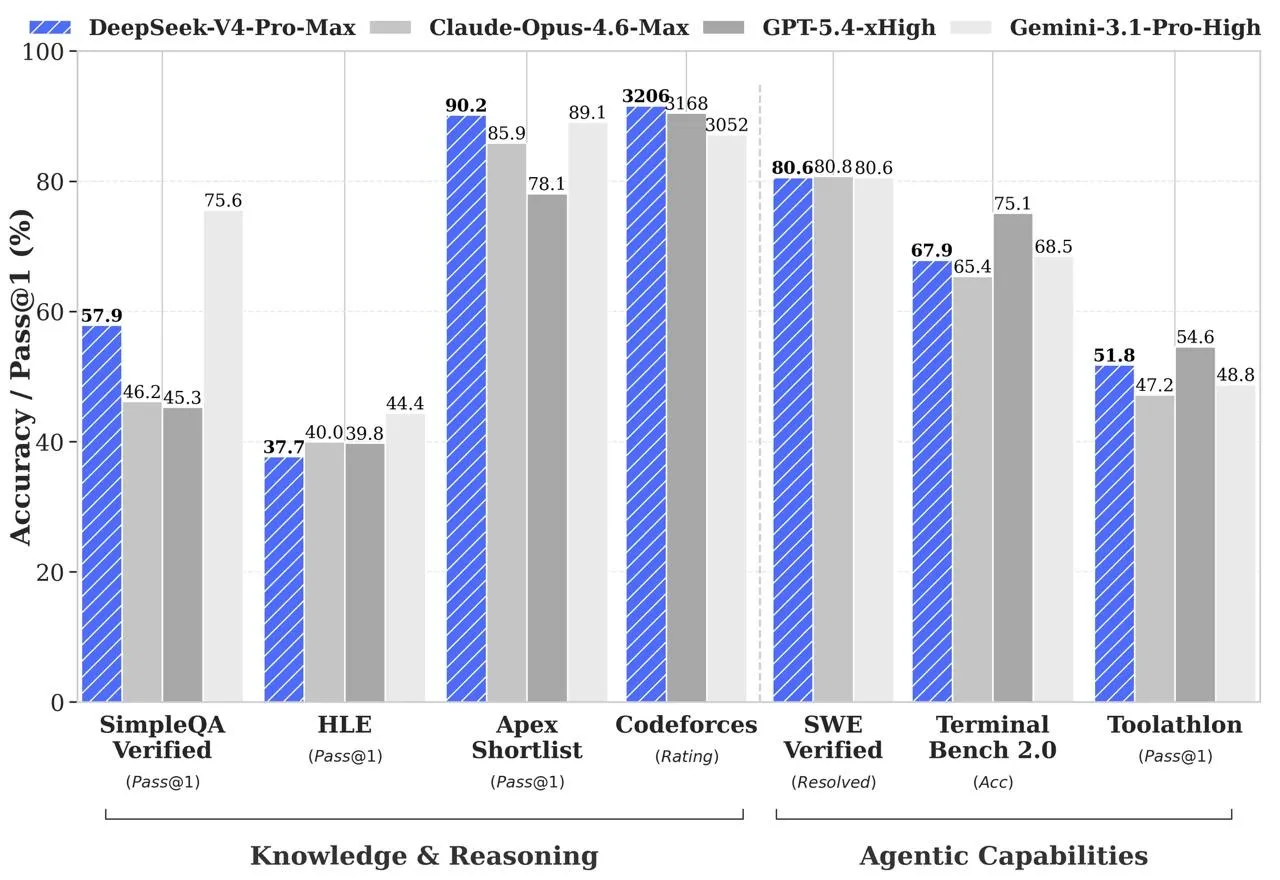 Источник: Hugging Face.
Источник: Hugging Face.
V4 специально тренировали на реальных сценариях: анализ данных, отчеты, редактирование документов, поиск в интернете с итеративным использованием инструментов.
Для оценки пригодности модели в реальной разработке стартап провел внутреннее тестирование на задачах своих инженеров. В опросе 85 разработчиков и исследователей 52% заявили, что готовы использовать V4-Pro как основную модель для кодинга, еще 39% отметили, что склоняются к такому решению.
Напомним, 23 апреля компания OpenAI выпустила GPT-5.5. Модель позиционируется как «новый уровень интеллекта для реальной работы и управления агентами».











