




К середине 2025 года около 35% новых веб-сайтов были созданы полностью или частично с помощью ИИ, выяснили исследователи Стэнфордского университета.
К середине 2025 года около 35% новых веб-сайтов были созданы полностью или частично с помощью искусственного интеллекта. К такому выводу пришли исследователи Стэнфордского университета.
До публичного запуска ChatGPT от OpenAI в ноябре 2022 года показатель находился у нуля. За несколько лет доля сгенерированного ИИ контента выросла до более чем трети последних публикаций в интернете.
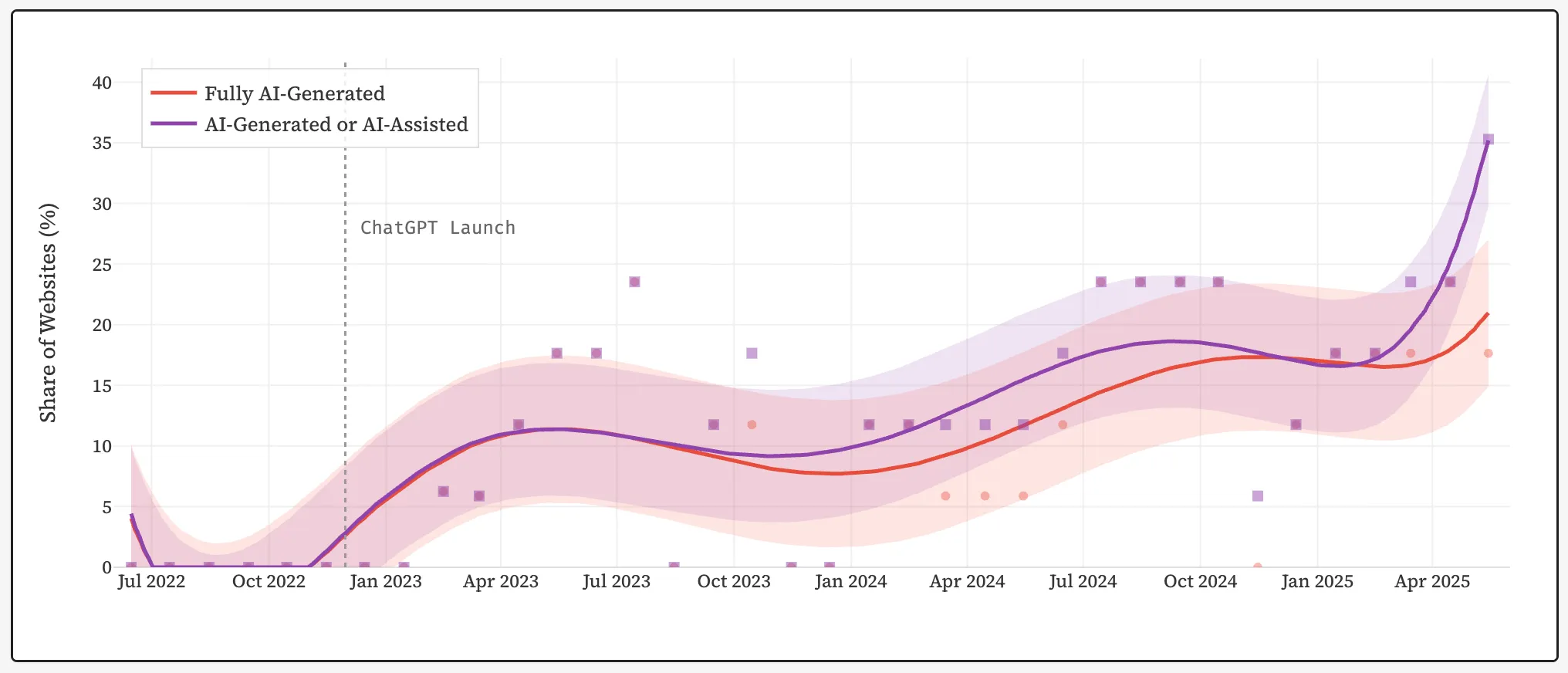 Доля сайтов, полностью сгенерированных ИИ (красный), а также созданных с помощью нейросетей (фиолетовый). Источник: GitHub.
Доля сайтов, полностью сгенерированных ИИ (красный), а также созданных с помощью нейросетей (фиолетовый). Источник: GitHub.
Ученые изучили 33 месяца архивных копий сайтов из Wayback Machine с помощью детектора Pangram v3. Целью было выяснить, как рост ИИ-текстов перестраивает структуру всемирной паутины.
Исследователи зафиксировали снижение семантического разнообразия. Сгенерированные нейросетями страницы на 33% больше похожи друг на друга, чем написанные людьми тексты. Разные сайты все чаще пересказывают одни и те же идеи практически идентичными фразами.
По мнению авторов, дело не просто в массовом копирайтинге с помощью ИИ. Проблема глубже: постепенно сужается разнообразие формулировок и идей. Большие языковые модели (LLM) по своей природе выбирают самые «усредненные» ответы и в результате воспроизводят шаблонный дискурс.
Изменился и эмоциональный тон публикаций. ИИ-контент оказался на 107% позитивнее человеческого. В Стэнфорде это связали уже задокументированной склонностью LLM к подхалимству.
В процессе обучения разработчики оптимизируют нейросети на приятные, безопасные и социально одобряемые ответы. В итоге значительная часть новых сайтов создает «стерильно дружелюбную» информационную среду. В ней меньше резких оценок и конфликтов, но и меньше живой человеческой полемики.
Несколько популярных опасений не нашли статистического подтверждения. Исследователи не обнаружили значимой корреляции между ростом ИИ-контента и снижением фактической точности, ростом числа явных ошибок или стилистическим выравниванием текстов до единого шаблона.
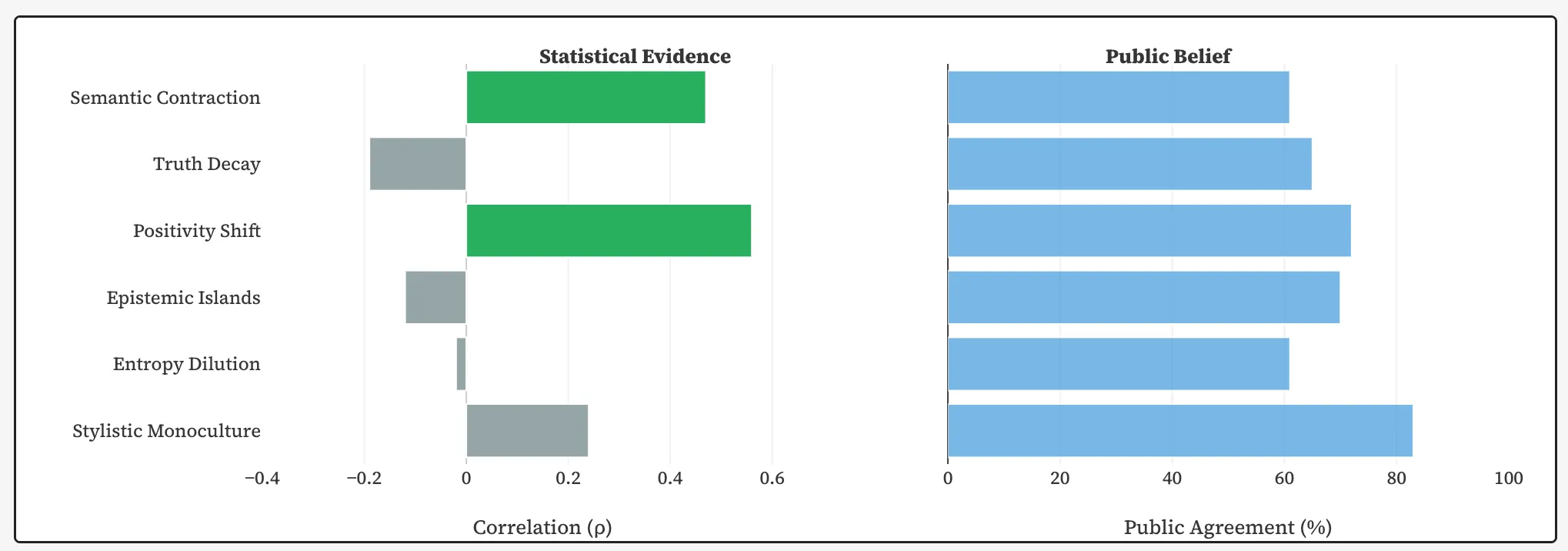 Слева: корреляция между ИИ-контентом и гипотезами. Справа: доля взрослых американцев, согласных с каждой гипотезой. Источник: GitHub.
Слева: корреляция между ИИ-контентом и гипотезами. Справа: доля взрослых американцев, согласных с каждой гипотезой. Источник: GitHub.
Ученые отдельно указали на эффект, который до сих пор обсуждался в основном теоретически, — коллапс модели (model collapse).
Если новые нейросети обучать на данных, где много ИИ-контента, система начинает переваривать свои же усредненные ответы. Это снижает вариативность, портит качество и грозит тем, что в дальнейшем LLM будут учиться не у людей, а у «синтетического эха» предшественниц.
Эксперты вместе с Internet Archive планирует превратить исследование в систему постоянного наблюдения за долей ИИ-контента в интернете.
Напомним, в середине апреля в Стэнфордском университете указали на опережающие темпы развития ИИ. Исследователи сообщили, что нейросети почти сравнялись с человеком в выполнении задач на компьютере.











